Índice de contenidos del artículo
Para entender JavaScript hay que saber que es un lenguaje interpretado. Esto quiere decir que el navegador, que es quien va a ejecutar el código, lo va leyendo línea por línea y lo va ejecutando paso a paso.
Por el contrario, los lenguajes compilados, primero compilan el código, es decir, lo traducen a lenguaje máquina y luego se ejecutan.
A nivel de uso, lo que ocurre es que si tenemos errores de sintaxis, en un lenguaje compilado, el programa se detendrá en la compilación y no llega a ejecutarse.
Sin embargo, en JavaScript, si tenemos un error de sintaxis, el navegador simplemente ignorará el código y continuará. Esto es así para que los sitios web siempre muestren la información, aunque no sea tal y como esperamos.
A este modo de proceder, se le llama Just in time compilation o compilación en el momento.
Veamos pues la ejecución de un script línea a línea y lo que ocurre en el sistema. Para ello, vamos a dividir la pantalla en dos zonas: El contexto de ejecución global (Global Execution Context) a la izquierda y la memoria global a la derecha, conocido en inglés como Global Variable Environment.
const num = 3;<br>
function multiplicarpor2 (numero){
const resultado = numero * 2;
return resultado;
}
const name = "Diego";En el vídeo anterior vemos que al ejecutar paso a paso, la función multiplica2 se guarda en memoria, pero como esta no es llamada, nunca entramos dentro de su código.
Cuando el sistema encuentra unos paréntesis (), sabe que se está encontrando una función. Digamos que es la forma de identificarlas.
Veamos un nuevo ejemplo en el que llamamos a la función:
const num = 3;
function multiplica2 (numero){
const resultado = numero * 2;
return resultado;
}
const salida = multiplica2(3);
const otraSalida = multiplica2(6);En el ejemplo anterior, vemos cómo la constante “salida” se asigna a la llamada a la función. En ese momento se crea un Local Execution Context o contexto de ejecución local, el cual tiene un hilo de ejecución local y memoria local.
Ejecutamos las instrucciones dentro de la función y enviamos el valor que devuelve a la variable “salida”. Después, el contexto de ejecución local termina para la llamada a la función y volvemos al contexto global.
Finalmente de vuelve a crear otro Local Execution Context para nueva llamada a la función en la asignación a la otra constante llamada “otraSalida”.
Imagina que la función se llama así misma dentro de su código. Esto se llama recursividad y con lo que hemos visto hasta ahora, perderíamos totalmente el control ante un caso así. Para gestionar el orden de llamadas está la pila de llamada o Call Stack.
Como su nombre indica, al ser una pila, los elementos entran y salen en orden LIFO (Last In, First Out), es decir, el último elemento que entra en la pila es el primero en ser atendido. Se pude hacer un símil con una pila de libros.
En el Call Stack siempre está el hilo de ejecución global en la parte de abajo, y los nuevos se van apilando (push) encima de este.
En este ejemplo, la primera llamada a la función multiplica2(3) se apila encima de Global, esta termina, se desapila (pop) y después se apila la nueva llamada multiplica2(10) encima de Global de nuevo.
El sistema sabe que finaliza una función debido a la sentencia return. Las funciones que no devuelven nada en realidad devuelven el valor por omisión, undefined (indefinido).
No es lo mismo asignar una función que la llamada a una función. Esto se define con los paréntesis. ¿Qué crees que mostrará console.log(multiplica2)?
Cuando ejecutamos una función, la única consecuencia que podemos esperar de ella es lo que haga la sentencia return. Esto quiere decir que nada del entorno global será alterado más allá de lo que haga el return.
Esto es muy ventajoso, ya que nos permite evaluar de manera independiente pequeños trozos de código y hacemos también que sea más fácil de leer por otros programadores o nosotros mismos en el futuro.
Una de las grandes máximas en programación es no reinventar la rueda y evitar repetirnos. El objetivo aquí es hacer código más genérico y más usable.
Consideremos el siguiente ejemplo:
function diezCuadrado (){
return 10*10;
}
console.log(diezCuadrado());La función anterior devuelve 10 al cuadrado, pero, si quisiéramos obtener 20 al cuadrado, tendríamos que crear otra función para resolver ese nuevo problema.
¿Y por qué no hacer una función más genérica que mediante un parámetro sea capaz de calcular el cuadrado de cualquier número?
Al hecho de parametrizar funciones lo llamamos generalizar las funciones.
function cuadrado (num){
return num*num;
}
console.log(cuadrado(5));Así hemos generalizado la función cuadrado para que calcule el cuadrado de cualquier número.
//Veamos paso a paso un nuevo ejemplo:
function copyYMulti(array){
let output=[];
for (let i=0; i < array.length; i++) {
output.push(array[i]*2);
}
return output;
}
const miArray = [1,2,3];
let resultado = copyYMulti(miArray);En el ejemplo anterior, en el momento en que entramos en el Local Execution Context de la función, lo que conocíamos como miArray pasa a ser [1,2,3]. El bucle va avanzando a través de los elementos del array y escribiendo el resultado en output con cada vuelta del bucle. Eso no está bien representado en la animación.
¿Y si hacemos paso a paso el siguiente código?
function copyYDivide(array){
let output=[];
for (let i=0; i < array.length; i++) {
output.push(array[i]/2);
}
return output;
}
const miArray = [1,2,3];
let resultado = copyYDivide(miArray);Obviamente el trabajo es prácticamente el mismo. Ese es el motivo por el que podemos generalizar de nuevo y la importancia de hacerlo.
Vamos pues a crear una función que nos permita enviarle como parámetro la operación:
function copyYOpera(array, operacion){
let output=[];
for (let i=0; i < array.length; i++) {
output.push(operacion(array[i]));
}
return output;
}
function duplica(num){
return num*2;
}
let resultado = copyYOpera([1,2,3], duplica);De ese modo, cuando la i del bucle es 0 en la primera iteración, cogemos el 1 del array y lo enviamos como parámetro de entrada a duplica sólo cuando ejecutamos la función principal, copyYOpera(), a través de operacion.
A copiaYOpera le pasamos como parámetro la función completa. Observa que no lleva paréntesis. Eso implica que no se ejecutará en ese momento. No está siendo llamada, sino que la estamos enviando completa con su funcionalidad.
Cuando entramos en el bucle se hace la llamada a duplica en cada vuelta de bucle, creando un nuevo Local Execution Context en cada iteración y encolándose la operación en la pila.
En JavaScript, las funciones se consideran First Class Objects (Objetos de Primera Clase), lo que implica que se comportan como objetos.
Sabemos que no hay problema en pasar objetos como parámetros de funciones, lo hemos visto en este mismo ejemplo, ya que pasamos un array a la función y un Array en JS es también un objeto.
Por tanto, las funciones pueden ser asignadas como variables o propiedades de otros objetos, ser pasadas como parámetros en funciones y ser devueltas como valores de retorno de otras funciones (la función completa).
Las funciones de primer orden, High-order functions, son funciones que llaman a otras funciones o que devuelven otras funciones.
Las funciones callback son aquellas que pasamos como parámetro de una función de primer orden.
En el ejemplo anterior, la función copyYOpera sería la de primer orden y la función duplica sería la función callback.
El uso de funciones primer orden y de callbacks hace el código más genérico y en consecuencia más limpio y escalable. Además, nos permite hacer uso de programación asíncrona.
A un closure o cierre lo podemos definir como la capacidad de acceder al scope padre desde el hijo, incluso cuando le ejecución de la función padre ya haya terminado.
Cuando llamamos a una función, creamos un almacén de datos en vivo de memoria local para su contexto de ejecución, al que llamamos entorno o estado de variable (Variable Environment).
Cuando una función termina su ejecución, su memoria local es eliminada por el recolector de basura (garbage collector), salvo el valor que devuelva. Pero, ¿y si las funciones pudieran mantener sus datos entre ejecuciones?
Eso son los cierres o closures y nos van a permitir disponer de memoria persistente.
Imagina que una una de las funciones que hemos empleado previamente, como multiplica2, fuera llamada muchas veces. Cada vez que la función es llamada, su ejecución comienza desde el principio. Si la operativa de esta función fuera costosa a nivel procesador, el hecho de tener que comenzar a ejecutarse desde el principio una y otra vez sería poco eficiente.
Veamos este código:
function creaInstruccion(){
function multiplica2(num){
return num*2;
}
return multiplica2;
}
let instruccionCreada = creaInstruccion();En el momento 6, cuando entra multiplica2 en la memoria local de creaInstrucción, si miráramos el inspector, veríamos la función completa. La función completa multiplica2 es por tanto lo que devuelve creaInstruccion y se asigna a instruccionCreada.
Después, creaInstrucción termina, pero tenemos en memoria, en la variable instruccionCreada, la función multiplica2. a la cual tenemos que pasarle un parámetro. Para ello debemos agregar una nueva línea de código.
let resultado = instruccionCreada(3); //6
En la nueva línea de código creamos una nueva variable llamada resultado, a la cual asignamos la variable instruccionCreada, que, como es como la función multiplica2, le debemos pasar un número como parámetro.
Veamos ahora otro ejemplo, ya que, la ubicación en que declaremos variables afectará a lo que pueden acceder las funciones:
function externa(){
let contador=0;
function incrementar(){
contador++;
}
incrementar();
}
externa();
Definimos el contador inicializado a 0 y cuando ejecutamos la llamada a la función incrementar y accedemos a sus datos, el sistema buscará contador en el entorno de variable local. Al no encontrarlo allí, sube un nivel y lo encontrará en la memoria local de la función externa.
Pero, ¿y si llamamos a la función fuera de dónde está definida?
function externa(){
let contador=0;
function incrementar(){
contador++;
}
}
externa();
incrementar();//??
No podríamos hacer eso a menos que devolvamos la función incrementar para poder acceder a sus datos.
function externa(){
let contador=0;
function incrementar(){
contador++;
}
return incrementar;
}
let nueva=externa();
//nueva = incrementar
En este caso, asignamos la llamada a la función externa a la variable nueva. Como la llamada a la función externa devuelve la función incrementar, nueva tendrá el código de la función incrementar.
En el momento final, todo lo que hay en el Execution Context de la llamada a la función externa desaparece.
A continuación, si quiero ejecutar la función que tengo almacenada en la variable nueva, debo agregar una nueva línea de código con la llamada (paréntesis).
nueva();
Estamos de nuevo en global, la ejecución de la función externa ha finalizado y el recolector de basura ha limpiado la memoria local, sin embargo, tengo en la variable nueva la función incrementar. Al llamar a la función nueva, se crea un nuevo contexto de ejecución.
En ese nuevo entorno de ejecución de la llamada a la función nueva, tratamos de incrementar la variable contador.
¿Qué sucede ahora?, ¿es posible acceder ahora a la variable contador? No existe la variable contador en memoria global y el recolector de basura ha limpiado el Variable Environment (VE) de la llamada a la función externa.
Lo que ocurre es que en el momento de devolver la función incrementar en la llamada a la función externa, se crea un vínculo con las variables que hay en ese entorno de variable (VE), de forma que en realidad se envían también los datos que están ahí en ese momento.
Por tanto, en el return, se envían las referencias a las variables del VE junto con la función. A este vínculo, que podemos llamar “mochila”, y es a lo que llamamos closure.
De esta forma, si volvemos a invocar a la función nueva, contador volverá a incrementarse como si fuera una variable global. Por tanto, podemos acceder a esas variables llamando a la función, siendo esta la única manera de hacerlo, lo cual, aporta seguridad, aparte de ahorro de memoria y de procesador.
Veamos otro ejemplo más ilustrativo:
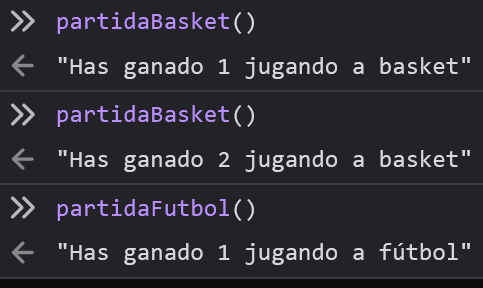
function crearJuego(nombreJuego) {
let puntos = 0;
return function ganar() {
puntos++;
return `Has ganado ${puntos} jugando a ${nombreJuego}`;
}
}
const partidaFutbol = crearJuego("fútbol");
const partidaBasket = crearJuego("basket");
¿Qué pasa si hay cierta parte del código que requiere esperar para recibir sus resultados? Por ejemplo, un cálculo largo o recuperar un recurso remoto.
Hasta ahora estamos ejecutando una cosa a la ves y en orden. Si tuviéramos que esperar a que la web recibiera un recurso remoto al que esté esperando, como por ejemplo, un tweet, el resto de la ejecución se detendría mientras ese tweet llega.
Afortunadamente, JavaScript tiene la capacidad de trabajar con esto con lo que llamamos asincronía. Veamos el siguiente código:
function diHola(){
console.log("Hola");
}
setTimeout(diHola,1000);
console.log("Yo primero");Si ejecutamos el código anterior veremos que aparece en prime lugar el mensaje “Yo primero” y un segundo después “Hola”. Podemos incrementar el 1000 de la función setTimeout para esperar más milisegundos y notarlo mejor.
La función setTimeout lo que hace esperar el número de milisegundos indicado en el segundo parámetro y luego ejecutar una llamada a la función que indicamos en el primer parámetro. Es una forma que tenemos de simular la asincronía.
Sin embargo, con lo que sabemos hasta ahora, lo lógico sería pensar que tras esperar un segundo, el sistema muestre en la consola el mensaje “Hola” y justo a continuación “Yo primero”.
¿Y si ejecutamos el mismo código, pero indicando en la función setTimeout que esperamos 0 milisegundos?
Para explicar esto disponemos de 3 conceptos que ya conocemos, el hilo de ejecucion (Thread of execution), el entorno de variable (VE) y la pila de llamadas (Call Stack); y 3 nuevos conceptos que veremos a continuación: APIs del navegador, la cola de tareas (Task queue o Callback) y el bucle de eventos (Event Loop).
Ejecutemos el siguiente código paso a paso:
function diHola(){
console.log("Hola");
}
setTimeout(diHola,0);
console.log("Yo primero");
¿Pero, qué pasa si yo ejecuto 20 veces console.log(“Yo primero”)? ¿Cuándo entra la llamada a diHola?
Veámoslo con este nuevo código:
function diHola(){
console.log("Hola");
}
function bloqueo1Seg(){
//se bloquea la ejecusión durante 1 segundo
}
setTimeout(diHola,0);
bloqueo1Seg();
console.log("Yo primero");La ejecución en este caso comienza igual que en el caso anterior. Entra setTimeout, que envía la función al Timer del navegador.
A continuación se ejecuta bloqueo1Seg, que se agrega a la pila, crea su contexto de ejecución y tarda 1 segundo en completarse.
Mientras tanto, el temporizador del navegador ha terminado sus 0ms. ¿Qué pasa ahora?
Entra en juego la cola de llamadas (Callback queue).
El temporizador del navegador envía la referencia a la función diHola a la cola en lugar de a la pila. Esta cola no enviará los elementos que contenga a la pila hasta que no se cumpla una condición. Que la pila esté vacía.
Sólo cuando la pila está vacía es cuando el bucle de eventos da la señal de apilar los elementos en la cola.
Por tanto, seguimos la ejecución en el hilo global. Termina bloqueo1Seg y ejecutamos console.log(“Yo primero”).
Después, la cola envía por fin la llamada a la función diHola() a la pila. Suponiendo que cada instrucción normal tarde 1ms en ejecutarse, veríamos en la consola en mensaje “Hola” en el milisegundo 1002 de la ejecución del script.
El proceso que detecta cuándo se vacía la pila y comprueba si hay elementos en la cola para enviar a la pila es el Event Loop o buble de eventos.
Imaginemos la situación de que enviamos varias llamadas a funcionalidades externas, APIs del navegador, APIs externas… y no sabemos cuándo termina cada una. Esto es lo que se conoce como Callback Hell, infierno de llamadas traducido.
Situaciones en las que se emplean las APIs del navegador y en las que, por tanto entremos dentro de este sistema de asincronía o Async en inglés, serían:
Veamos un nuevo ejemplo con otro tipo funcionalidad del navegador, en este caso una petición http, XML http Request.
function mostrar(datos){
console.log(datos.post);
}
$.get("http://twitter.com/...", mostrar);
console.log("Yo primero");Suponemos que disponemos de la función get de Jquerry, la cual habla con el navegador para obtener datos externos de la página de Twitter.
Mientras get espera a recibir los datos del servidor, la ejecución global continúa y se muestra el mensaje en el log.
Unos 200ms más tarde, get obtiene los datos y envía la llamada a mostrar(datos) al callback y posteriormente al call stack, por estar la pila vacía.
La función mostrar genera un nuevo entorno de ejecución local en el que recibe los datos para ser a continuación enviados al log.
Llegados a este punto, lo normal sería hacer algo con esos datos en lugar de simplemente mostrarlos, por lo que, en este entorno de ejecución local que crea la función display, podríamos hacer otra llamada a otro servicio externo como almacenar esos datos en una base de datos. Esto sería otro ejemplo del antes mencionado callback hell y el porqué de las promesas (promises).
